配置
在为你的电脑安装完Git之后,因为Git是分布式版本控制系统,所以,每个机器都必须自报家门:你的名字和Email地址。你也许会担心,如果有人故意冒充别人怎么办?这个不必担心,首先我们相信大家都是善良无知的群众,其次,真的有冒充的也是有办法可查的。
注意git config命令的--global参数,用了这个参数,表示你这台机器上所有的Git仓库都会使用这个配置,当然也可以对某个仓库指定不同的用户名和Email地址。
1 | $ git config --global user.name "Your Name" |
你可以在任何一个目录下进行git init操作,让Git系统来跟踪记录你的文件的修改情况。
工作区、暂存区以及版本库
Git 工作区里面有一个隐藏目录.git,这个是Git 的版本库,一般作为隐藏目录存放,而不是工作区。
Git的版本库里存了很多东西,其中最重要的就是称为stage(或者叫index)的暂存区,还有Git为我们自动创建的第一个分支master,以及指向master的一个指针叫HEAD。
如果你使用了git add <file>,操作正确之后则会将文件存储在stage暂存,然后使用git commit -m "Info"之后才会
提交添加到master分支上。commit面向多文件提交,add一般指向单文件;这时,你可以使用git status来查看版本库的状态。
其中HEAD指针指向当前版本
版本回退
我们有时候要回退到之前文件的某个状态,可以使用git log来查看 从最近到最远的提交的日志,记录了你做了什么操作;
你也可以在后面加上--pretty=oneline让显示更加人性化。如
1 | git log --pretty=oneline |
你看到的一大串类似1094adb...的是commit id(版本号),和SVN不一样,Git的commit id不是1,2,3……递增的数字,而是一个SHA1计算出来的一个非常大的数字,用十六进制表示,而且你看到的commit id和我的肯定不一样,以你自己的为准。为什么commit id需要用这么一大串数字表示呢?因为Git是分布式的版本控制系统,后面我们还要研究多人在同一个版本库里工作,如果大家都用1,2,3……作为版本号,那肯定就冲突了。
每提交一个新版本,实际上Git就会把它们自动串成一条时间线。如果使用可视化工具查看Git历史,就可以更清楚地看到提交历史的时间线:
在Git中,用HEAD表示当前版本,也就是最新的提交1094adb...(注意我的提交ID和你的肯定不一样),上一个版本就是HEAD^,上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100。
你可以使用git reset --hard HEAD^向前回退到上一版本。
你可以使用git reset HEAD <file>可以把暂存区的修改撤销掉(unstage),重新放回工作区。当我们用HEAD时,表示最新的版本。
你也可以使用git reflog来查看你的每一次命令,从而找到之前的commit id,向后回退到未来的哪个版本。
也可以使用git reset --hard 1094a回退到指定版本,版本号没必要写全,前几位就可以了,Git会自动去找。当然也不能只写前一两位,因为Git可能会找到多个版本号,就无法确定是哪一个了。
管理修改
注意,如果我们对某一文件进行:第一次修改 -> git add -> 第二次修改 -> git commit
那么,第一次的修改被提交了,第二次的修改不会被提交,这是因为git commit只负责把暂存区的修改提交了;
当你用git add命令后,在工作区的第一次修改被放入暂存区,准备提交,但是,在工作区的第二次修改并没有使用add放入暂存区
你可以使用git diff HEAD -- <file>来查看该文件的所有修改情况
你可以使用git checkout -- <file>来撤销你的修改。如果修改之前你已经将文件add到了暂存区,但还没commit,这时撤销修改后,就回到添加到暂存区后的状态,对实现这一操作目的的另一种做法是:
使用git reset HEAD <file>把暂存区的修改撤销掉(unstage),重新放回工作区。
注意:当我们用HEAD时,表示最新的版本。
如果修改后还没有被放到暂存区,现在,撤销修改就回到和版本库一模一样的状态。
又到了小结时间。
场景1:当你改乱了工作区某个文件的内容,想直接丢弃工作区的修改时,用命令git checkout -- file。
场景2:当你不但改乱了工作区某个文件的内容,还添加到了暂存区时,想丢弃修改,分两步,第一步用命令git reset HEAD <file>,就回到了场景1,第二步按场景1操作。
场景3:已经提交了不合适的修改到版本库时,想要撤销本次提交,参考上一节版本回退,不过前提是没有推送到远程库。
删除文件
一般情况下,你通常直接在文件管理器中把没用的文件删了,或者用rm命令删了:rm test.txt
这个时候,Git知道你删除了文件,因此,工作区和版本库就不一致了。现在你有两个选择,一是确实要从版本库中删除该文件,那就用命令git rm删掉,并且git commit:
1 | git rm test.txt |
另一种情况是删错了,因为版本库里还有呢,所以可以很轻松地把误删的文件恢复到最新版本:
1 | git checkout -- test.txt |
git checkout其实是用版本库里的版本替换工作区的版本,无论工作区是修改还是删除,都可以“一键还原”。
注意:从来没有被添加到版本库就被删除的文件,是无法恢复的!命令git rm用于删除一个文件。如果一个文件已经被提交到版本库,那么你永远不用担心误删,但是要小心,你只能恢复文件到最新版本,你会丢失最近一次提交后你修改的内容。
远程仓库
找一台电脑充当服务器的角色,每天24小时开机,其他每个人都从这个“服务器”仓库克隆一份到自己的电脑上,并且各自把各自的提交推送到服务器仓库里,也从服务器仓库中拉取别人的提交。GitHub这个网站就是提供Git仓库托管服务的,
你的本地Git仓库和GitHub仓库之间的传输是通过SSH加密的,需要配置SSH key的密钥对。
Git 服务器上存储的是公钥,你本地存储的是私钥,当你push本地代码库到远程代码库,服务器会要求你出示私钥,并且用你出示的私钥和它的公钥配对来完成认证。由于使用的是不对称加密,所以公钥可以公开,只要保管好私钥就可以。
关于密钥技术的相关知识,你可以访问:我的博客文章:
在Github上创建一个learngit仓库后,你可以根据GitHub的提示,在本地的learngit仓库下运行以下命令,你在本地关联的就是用户YourName的learngit远程库。
1 | git remote add origin git@github.com:Name/learngit.git |
然后,可以使用
1 | git push -u origin master |
由于远程库是空的,我们第一次推送master分支时,加上了-u参数,Git不但会把本地的master分支内容推送的远程新的master分支,还会把本地的master分支和远程的master分支关联起来,在以后的推送或者拉取时就可以简化命令。
从现在起,只要本地作了提交,就可以通过命令:
1 | git push origin master |
把本地master分支的最新修改推送至GitHub,现在,你就拥有了真正的分布式版本库!
SSH警告
当你第一次使用Git的clone或者push命令连接GitHub时,会得到一个警告:
1 | The authenticity of host 'github.com (xx.xx.xx.xx)' can't be established. |
这是因为Git使用SSH连接,而SSH连接在第一次验证GitHub服务器的Key时,需要你确认GitHub的Key的指纹信息是否真的来自GitHub的服务器,输入yes回车即可。
Git会输出一个警告,告诉你已经把GitHub的Key添加到本机的一个信任列表里了:
1 | Warning: Permanently added 'github.com' (RSA) to the list of known hosts. |
这个警告只会出现一次,后面的操作就不会有任何警告了。
如果你实在担心有人冒充GitHub服务器,输入yes前可以对照GitHub的RSA Key的指纹信息是否与SSH连接给出的一致。
小结
要关联一个远程库,使用命令git remote add origin git@server-name:path/repo-name.git;
关联后,使用命令git push -u origin master第一次推送master分支的所有内容;
此后,每次本地提交后,只要有必要,就可以使用命令git push origin master推送最新修改;
分布式版本系统的最大好处之一是在本地工作完全不需要考虑远程库的存在,也就是有没有联网都可以正常工作,而SVN在没有联网的时候是拒绝干活的!当有网络的时候,再把本地提交推送一下就完成了同步,真是太方便了!
要克隆一个仓库,首先必须知道仓库的地址,然后使用git clone命令克隆。
Git支持https协议,也就是说你可以使用像https://github.com/michaelliao/gitskills.git这样的地址,但通过ssh支持的原生git协议速度最快。使用https除了速度慢以外,还有个最大的麻烦是每次推送都必须输入口令,但是在某些只开放http端口的公司内部就无法使用ssh协议而只能用https。
1 | git clone git@github.com:Name/learngit.git |
实际上,Git支持多种协议,默认的git://使用ssh。
分支管理
分支在实际中有什么用呢?假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码,如果立刻提交,由于代码还没写完,不完整的代码库会导致别人不能干活了。如果等代码全部写完再一次提交,又存在丢失每天进度的巨大风险。
现在有了分支,就不用怕了。你创建了一个属于你自己的分支,别人看不到,还继续在原来的分支上正常工作,而你在自己的分支上干活,想提交就提交,直到开发完毕后,再一次性合并到原来的分支上,这样,既安全,又不影响别人工作。
其他版本控制系统如SVN等都有分支管理,但是用过之后你会发现,这些版本控制系统创建和切换分支比蜗牛还慢,简直让人无法忍受,结果分支功能成了摆设,大家都不去用。
但Git的分支是与众不同的,无论创建、切换和删除分支,Git在1秒钟之内就能完成!无论你的版本库是1个文件还是1万个文件。
在Git里面,每次提交,Git都把它们串成一条时间线,这条时间线就是一个分支。
Git 会使用 master 作为分支的默认名字。在若干次提交后,你其实已经有了一个指向最后一次提交对象的 master 分支,它在每次提交的时候都会自动向前移动。
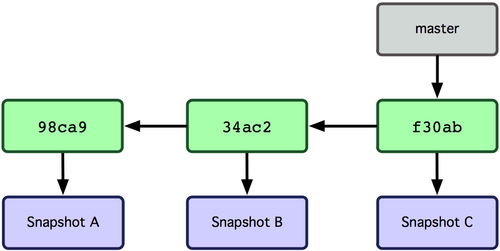
那么,Git 是如何知道你当前在哪个分支上工作的呢?其实答案也很简单,它保存着一个名为 HEAD 的特别指针。
在 Git 中,它是一个指向你正在工作中的本地分支的指针(将 HEAD 想象为当前分支的别名。)。
运行git branch` 命令,仅仅是建立了一个新的分支,但不会自动切换到这个分支中去,所以在这个例子中,我们依然还在 master 分支里工作。
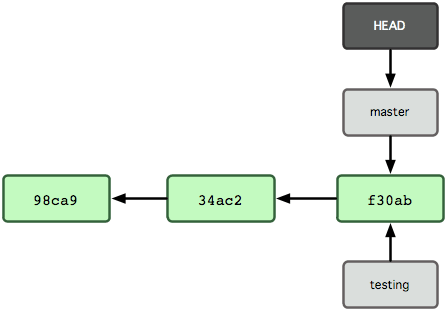
我们现在转换到新建的 testing分支:
git checkout testing
然后HEAD就指向了testing分支:
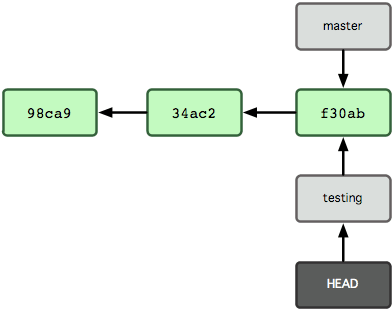
提交文件后,现在 testing 分支往前移动了一格:
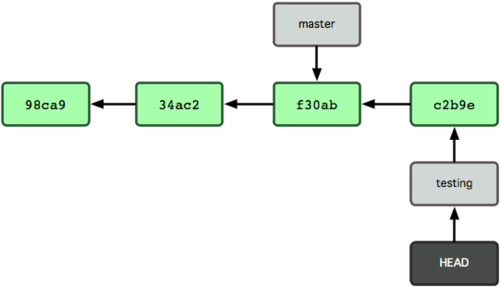
我们使用:git checkout master之后,HEAD 在一次 checkout 之后移动到了另一个分支,回到master分支上了:
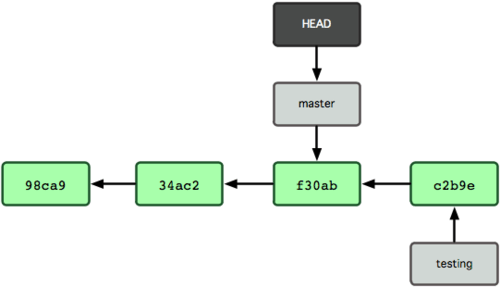
下面与分支有关的常用命令:
查看分支:git branch
创建分支:git branch <name>
切换分支:git checkout <name>
创建+切换分支:git checkout -b <name>
合并某分支到当前分支:git merge <name>
删除分支:git branch -d <name>
如果在合并的分支中,有相同的文件但是拥有不一样的内容时,就会发生冲突,就必须首先解决冲突。解决冲突后,再提交,合并完成。
例如:我们在master和新创建的newbranch分支上,都分别修改了工作区的readme.txt,并都进行了add操作,
但是由于修改的内容不同,这时候,分支合并就会出现异常:
你可以使用git status或者cat readme.txt查看文件冲突:例如:
1 | <<<<<<< HEAD |
Git用<<<<<<<,=======,>>>>>>>标记出不同分支的内容,我们修改如下后保存:
1 | Creating a new branch is quick and simple. |
再提交:
1 | git add readme.txt |
提交之后,分支延长,
现在,master分支和feature1分支变成了下图所示:(有同一向右的目的表示合并)
用带参数的git log --graph也可以看到分支的合并情况:
1 | git log --graph --pretty=oneline --abbrev-commit |
最后,删除feature1分支:
1 | git branch -d feature1 |
如果要丢弃一个没有被合并过的分支,可以通过git branch -D <name>强行删除。
在实际开发中,我们应该按照几个基本原则进行分支管理:
首先,master分支应该是非常稳定的,也就是仅用来发布新版本,平时不能在上面干活;
那在哪干活呢?干活都在dev分支上,也就是说,dev分支是不稳定的,到某个时候,比如1.0版本发布时,再把dev分支合并到master上,在master分支发布1.0版本;
你和你的小伙伴们每个人都在dev分支上干活,每个人都有自己的分支,时不时地往dev分支上合并就可以了。
所以,团队合作的分支看起来就像这样:
现在,如果你在当前状态下工作,但是其他地方需要紧急处理,你可以使用git stash来保存工作区的当前状态,此状态信息将会保存到栈中。你可以使用git stash list查看所有保存的状态。
你可以使用git stash apply恢复之前的状态,但恢复之后栈内的相应的状态信息记录不会被删除,你可以使用git stash drop来删除;你可以使用git stash pop来代替这恢复——删除的操作。
多人协作
当你从远程仓库克隆时,实际上Git自动把本地的master分支和远程的master分支对应起来了,并且,远程仓库的默认名称是origin。
本地分支往远程推送,需要同远程进行同步,需要注意本地分支:
- 因为
master与远程master分支同步,所以需要时刻与远程同步; - 开发分支,团队所有成员都需要在上面工作,所以也需要与远程同步;
- 你本人增加的用于修复
bug的分支只用于在本地修复bug,就没必要推到远程了,除非老板要看看你每周到底修复了几个bug; - 对于为新功能开发增加的新分支是否推到远程,取决于你是否和你的小伙伴合作在上面开发。
总之,就是在Git中,分支完全可以在本地自己藏着玩,是否推送,视你的心情而定!
要查看远程库的信息,可以使用git remote命令,或者使用git remote -v来查看更加详细的信息。
要从远程库中获取最新分支信息,并将该分支信息与本地分支信息进行合并,你可以使用
git pull ##远程主机(origin) #远程分支(next)#:#本地分支(master)#
如果远程分支是与当前分支合并,则冒号后面的部分可以省略。
推送分支
你可以使用git push origin <branch-name>将本地的branch-name分支向远程仓库推送,如果推送失败,则是因为远程分支比你的分支更新,需要解决冲突再推送。
接下来,当你的协作者再次从服务器上获取数据时,他们将得到一个新的远程分支 origin/<branch-name>
如果要把该远程分支的内容合并到当前分支,可以运行 git merge origin/<branch-name>
如果想在远程分支的基础上分化出一个新的分支来: git checkout -b <local-branch> origin/<branch-name>
这会切换到新建的 local-branch本地分支,这样你就可以在里面继续开发了。
建立关联并合并
你可以使用以下命令建立本地当前的分支与远程分支的关联:
1 | git branch --set-upstream-to = origin/<remote-branch> <local-branch> |
然后使用git pull将所有有关联的远程分支和本地分支进行合并。
如果git pull提示no tracking information,则说明本地分支和远程分支的关联没有创建
因此,多人协作的工作模式通常是这样:
- 首先,可以试图用
git push origin <branch-name>推送自己的修改; - 如果推送失败,则因为远程分支比你的本地更新,需要先用
git pull试图合并; - 如果合并有冲突,则解决冲突,并在本地提交;
- 没有冲突或者解决掉冲突后,再用
git push origin <branch-name>推送就能成功!
如果git pull提示no tracking information,则说明本地分支和远程分支的链接关系没有创建,用命令git branch --set-upstream-to <branch-name> origin/<branch-name>。
这就是多人协作的工作模式,一旦熟悉了,就非常简单。
标签管理
标签总是和某个commit挂钩。如果这个commit既出现在master分支,又出现在dev分支,那么在这两个分支上都可以看到这个标签。
你可以按照简单易记的标签与复杂的commit id对应起来。
你可以使用类似的:git tag <tag-name> f52c633语句来为指定commit id附上标签。
如果你不加上上面f52c633参数,则默认为HEAD指向的commit id打标签。
还可以创建带有说明的标签,用-a指定标签名,-m指定说明文字:
1 | git tag -a <tag-name> -m "version 0.1 released" 1094adb |
使用git tag查看当前存在的所有标签;
使用git tag <tag-name>查看指定标签的详细信息;
如果要推送某个标签到远程,可以使用命令git push origin <tag-name>;
也可一次性推送全部尚未推送到远程的本地标签:$ git push origin --tags;
你也可以使用git tag -d <tag-name>来删除标签;
如果标签已经推送到远程,要删除远程标签就麻烦一点,先从本地删除tag1:
$ git tag -d tag1
然后,从远程删除。删除命令也是push,但是格式如下:
$ git push origin :refs/tags/tag1
GitHub使用
- 在
GitHub上,可以任意Fork开源仓库; - 自己拥有
Fork后的仓库的读写权限; - 可以推送
pull request给官方仓库来贡献代码。
使用GitHub时,国内的用户经常遇到的问题是访问速度太慢,有时候还会出现无法连接的情况(原因你懂的)。
如果我们希望体验Git飞一般的速度,可以使用国内的Git托管服务——码云(gitee.com)。
自定义Git
让Git显示颜色,会让命令输出看起来更醒目:
1 | $ git config --global color.ui true |
忽略特殊文件:
在Git工作区的根目录下创建一个特殊的.gitignore文件,然后把要忽略的文件名填进去,Git 就会自动忽略这些文件。
有些时候,你想添加一个文件到Git,但发现添加不了,原因是这个文件被.gitignore忽略了,
如果你确实想添加该文件,可以用-f强制添加到Git:
git add -f <file>
.gitignore文件本身要放到版本库里,并且可以对.gitignore做版本管理。
可以用git check-ignore命令检查忽略文件是否存在.gitignore文件中,
git check-ignore -v <file>
更改命令别名
你可以使用git config --global alias.<another-name> <origin-name>给origin-name命令起别名another-name
配置Git的时候,加上--global是针对当前用户起作用的,如果不加,那只针对当前的仓库起作用。
你可以在配置文件中查找别名:
cat .git/config
当前用户的Git配置文件放在用户主目录下的一个隐藏文件.gitconfig中:
别名就在[alias]后面,要删除别名,直接把对应的行删掉即可。配置别名也可以直接修改这个文件,如果改错了,可以删掉文件重新通过命令配置。
搭建Git服务器
GitHub就是一个免费托管开源代码的远程仓库。但是对于某些视源代码如生命的商业公司来说,既不想公开源代码,又舍不得给GitHub交保护费,那就只能自己搭建一台Git服务器作为私有仓库使用。
搭建Git服务器需要准备一台运行Linux的机器,强烈推荐用Ubuntu或Debian,这样,通过几条简单的apt命令就可以完成安装。
假设你已经有sudo权限的用户账号,下面,正式开始安装。
第一步,安装git:
1 | $ sudo apt-get install git |
第二步,创建一个git用户,用来运行git服务:
1 | $ sudo adduser git |
第三步,创建证书登录:
收集所有需要登录的用户的公钥,就是他们自己的id_rsa.pub文件,把所有公钥导入到/home/git/.ssh/authorized_keys文件里,一行一个。
第四步,初始化Git仓库:
先选定一个目录作为Git仓库,假定是/srv/sample.git,在/srv目录下输入命令:
1 | $ sudo git init --bare sample.git |
Git就会创建一个裸仓库,裸仓库没有工作区,因为服务器上的Git仓库纯粹是为了共享,所以不让用户直接登录到服务器上去改工作区,并且服务器上的Git仓库通常都以.git结尾。然后,把owner改为git:
1 | $ sudo chown -R git:git sample.git |
第五步,禁用shell登录:
出于安全考虑,第二步创建的git用户不允许登录shell,这可以通过编辑/etc/passwd文件完成。找到类似下面的一行:
1 | git:x:1001:1001:,,,:/home/git:/bin/bash |
改为:
1 | git:x:1001:1001:,,,:/home/git:/usr/bin/git-shell |
这样,git用户可以正常通过ssh使用git,但无法登录shell,因为我们为git用户指定的git-shell每次一登录就自动退出。
第六步,克隆远程仓库:
现在,可以通过git clone命令克隆远程仓库了,在各自的电脑上运行:
1 | $ git clone git@server:/srv/sample.git |
剩下的推送就简单了。
管理公钥
如果团队很小,把每个人的公钥收集起来放到服务器的/home/git/.ssh/authorized_keys文件里就是可行的。如果团队有几百号人,就没法这么玩了,这时,可以用Gitosis来管理公钥。
这里我们不介绍怎么玩Gitosis了,几百号人的团队基本都在500强了,相信找个高水平的Linux管理员问题不大。
管理权限
有很多不但视源代码如生命,而且视员工为窃贼的公司,会在版本控制系统里设置一套完善的权限控制,每个人是否有读写权限会精确到每个分支甚至每个目录下。因为Git是为Linux源代码托管而开发的,所以Git也继承了开源社区的精神,不支持权限控制。不过,因为Git支持钩子(hook),所以,可以在服务器端编写一系列脚本来控制提交等操作,达到权限控制的目的。Gitolite就是这个工具。
这里我们也不介绍Gitolite了,不要把有限的生命浪费到权限斗争中。
